我們今天來回顧前面架構出來的建議深度學習模型(手寫數字辨識),只要在構建好的模型後寫上「model.summary()」就可以印出模型摘要,如下圖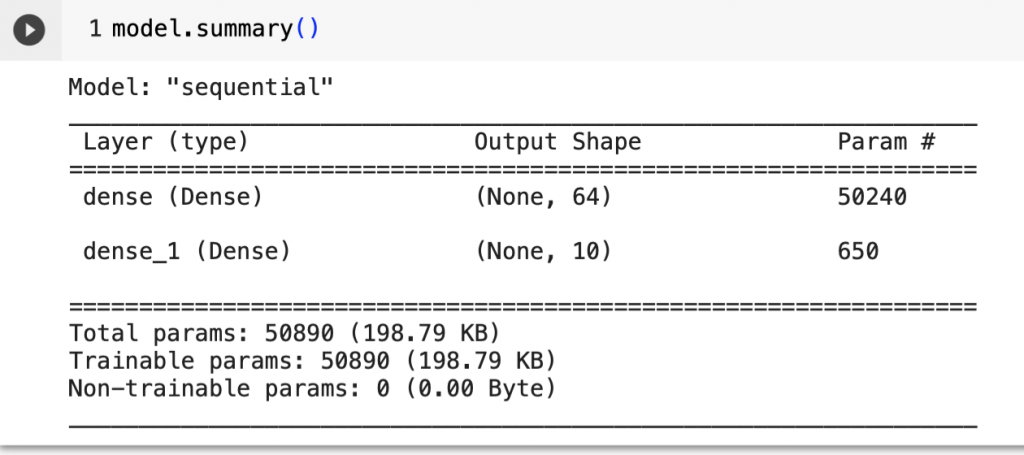
那這時候你可能會好奇應該也要有輸入層還有輸出層啊?那其實輸入層只是單純接收資料並傳入隱藏層,沒有做任何的計算功能,因此我們的摘要沒有顯示,此外輸出層則是因為第二個隱藏層兼具輸出層所以才沒有。
這次的輸入層接收784個神經元(28 * 28個像素值),然後我們設定第一個隱藏層有64個神經元,所以輸入層與第一隱藏層之間有50176個權重(784 * 64),忘記的人可以回去複習是否為垃圾郵件的那張圖,這時候你可能會發現這與Param出現的數字不一樣,沒錯!那是因為我們還需要加上一個值b,這個b值我們稱為偏值,在第一隱藏層中每個神經元都會加上一個偏值,因為有64個神經元,所以公式會長這樣x(784神經元) * w(64權重) +b(64偏值)=50240
依照這樣的概念大家可以試著想想看第二隱藏的邏輯是怎麼運行的呢?
答案是64 * 10 +10=650,是不是很容易就能理解呢?
那50176與650代表什麼意思呢?
就是要訓練出50176+650=50890個參數的最佳值!


 iThome鐵人賽
iThome鐵人賽